
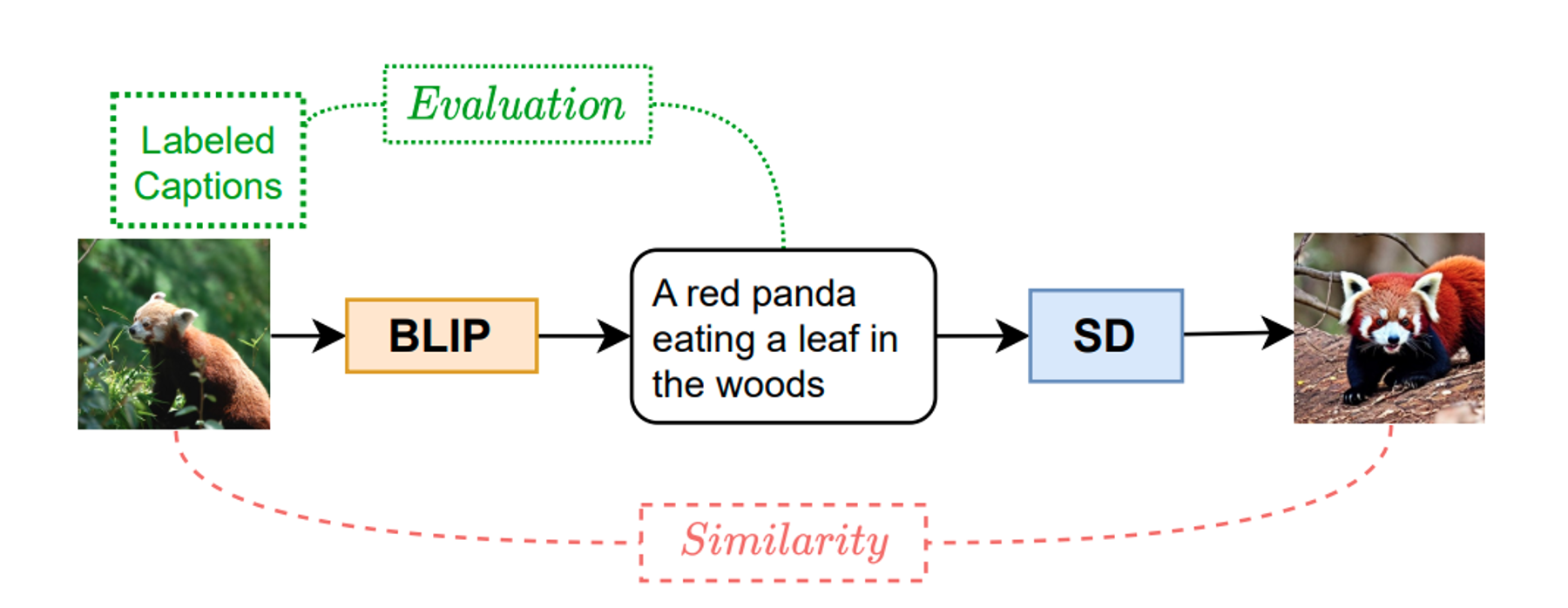
The field of multimodal research focusing on the comprehension and creation of both images and text has witnessed significant strides. This progress is exemplified by the emergence of sophisticated models dedicated to image captioning at scale, such as the notable Flamingo model and text-to-image generative models, with DALL-E serving as a prominent example. An interesting question worth exploring in this domain is whether Flamingo and DALL-E understand each other. To study this question, we propose a reconstruction task where Flamingo generates a description for a given image and DALL-E uses this description as input to synthesize a new image. We argue that these models understand each other if the generated image is similar to the given image. Specifically, we study the relationship between the quality of the image reconstruction and that of the text generation. We find that an optimal description of an image is one that gives rise to a generated image similar to the original one. The finding motivates us to propose a unified framework to finetune the text-to-image and image-to-text models. Concretely, the reconstruction part forms a regularization loss to guide the tuning of the models. Extensive experiments on multiple datasets with different image captioning and image generation models validate our findings and demonstrate the effectiveness of our proposed unified framework. As DALL-E and Flamingo are not publicly available, we use Stable Diffusion and BLIP in the remaining work.
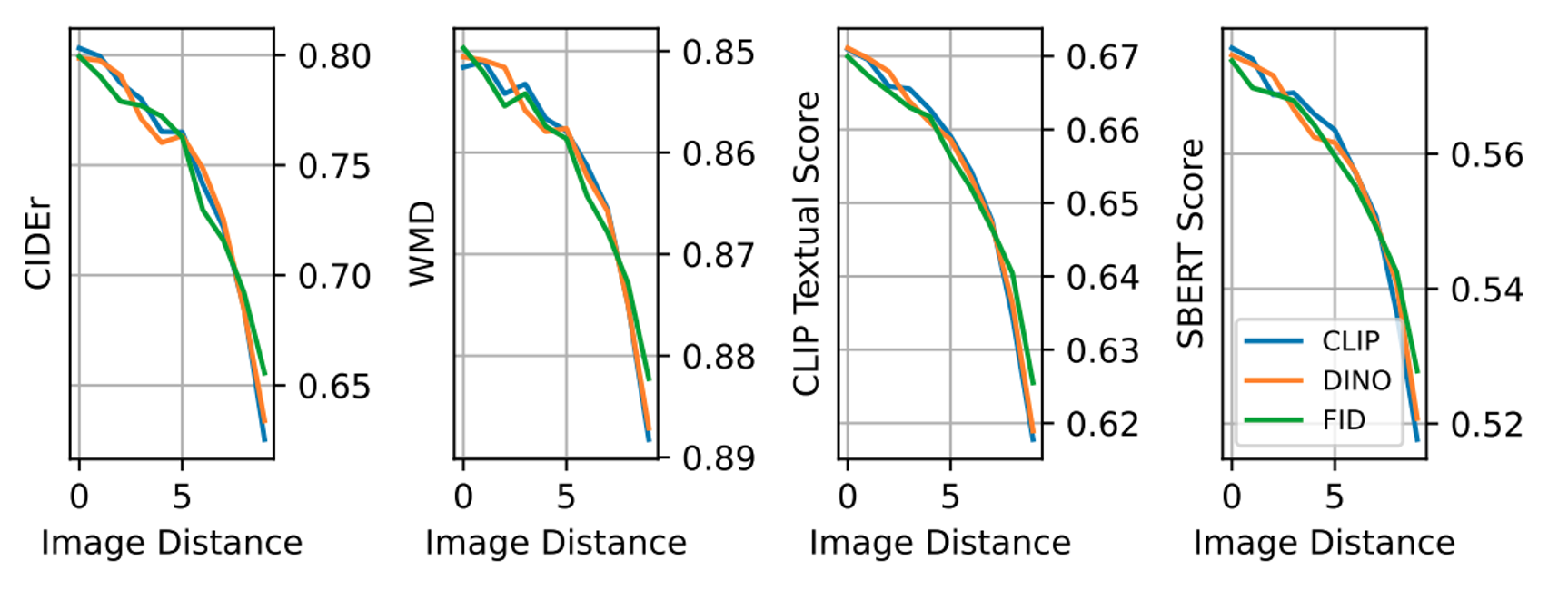
The quality of a caption can be evaluated by assessing the image reconstruction produced by a text-to-image model. The best text for an image is one that leads to the most accurate reconstruction of the original image
Method: The generated image is compared with the input image using a similarity function based on CLIP image embeddings. Human-annotated captions serve as ground truth representations of the input image to evaluate the quality of the generated caption.
Qualitative examples of reconstruction tasks. The figure shows image reconstruction for the given input image of a bird. Two samples are shown with their generated images, ranked by the image similarity.

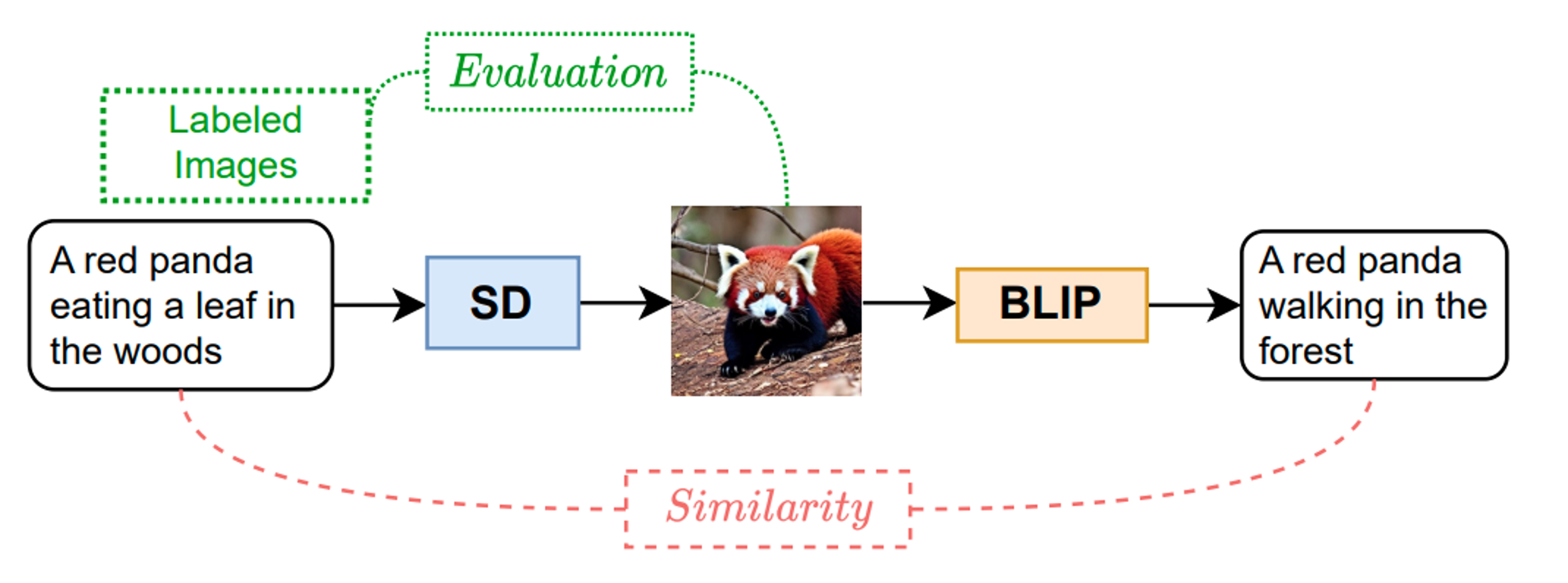
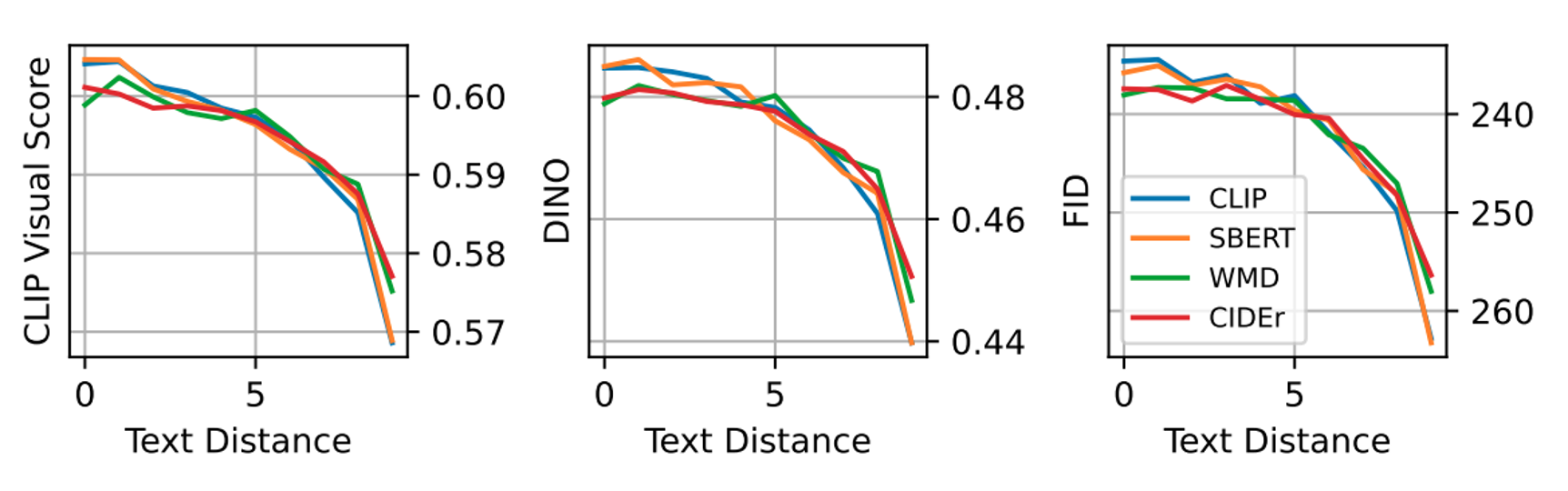
The quality of a generated image can be evaluated by assessing the text reconstruction produced by a caption model. The best image for an image is one that leads to the most accurate reconstruction of the original text.
Method: The generated image is compared with the input image using a similarity function based on CLIP image embeddings. Human-annotated captions serve as ground truth representations of the input image to evaluate the quality of the generated caption.
Qualitative examples of reconstruction tasks. The figure shows text reconstruction for the given input image of a text. Two samples are shown with their generated texts, ranked by the image similarity.

More Visualizations:


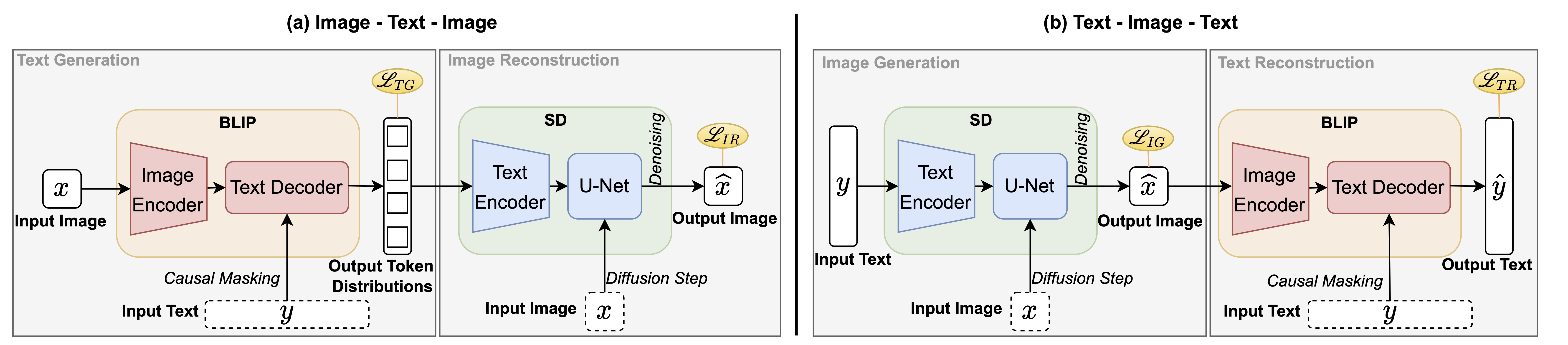
A Finetuning Framework We propose a unified framework to enhance both the image-to-text and text-to-image models: finetuning the image-to-text model using a reconstruction loss computed by a text-to-image model as regularization.
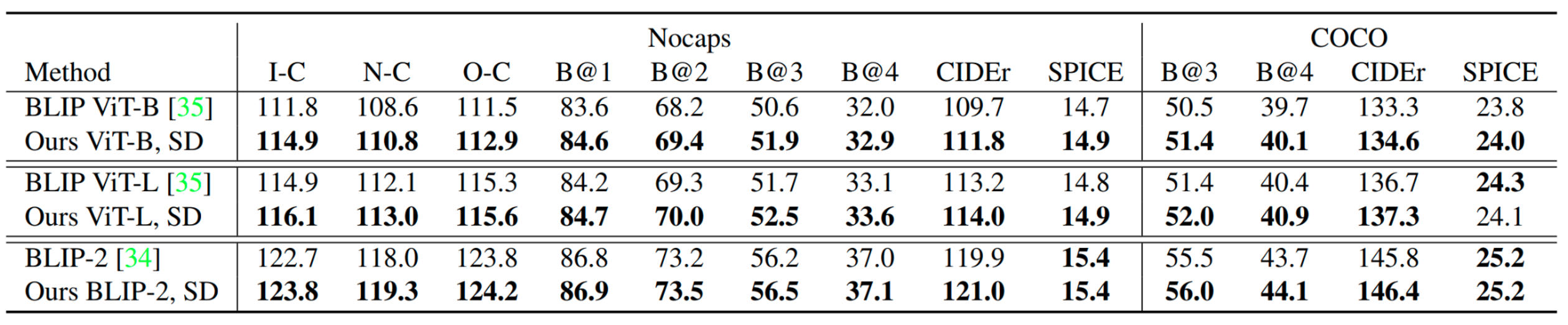
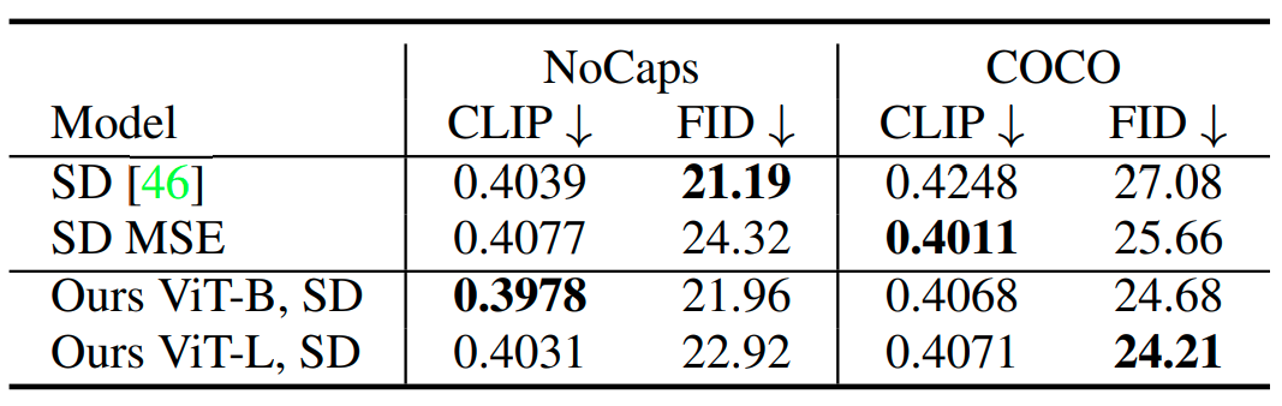
Improvement: Image-to-Text Captioning task
@InProceedings{li2023dall,
author = {Li, Hang and Gu, Jindong and Koner, Rajat and Sharifzadeh, Sahand and Tresp, Volker},
title = {Do DALL-E and Flamingo Understand Each Other?},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {1999-2010}
}